

Following on from the announcement by the development team at Stability AI about the launch of its new AI sound generator aptly named Stable Audio. This quick overview guide will dive a little deeper into the technology and datasets used to train the AI sound generation website that can create not only sound effects but also music in seconds.
Within artificial intelligence technologies, diffusion-based generative models have made significant strides in enhancing the quality and controllability of generated images, video, and audio. These models, particularly latent diffusion models, operate in the latent encoding space of a pre-trained autoencoder, offering substantial speed improvements in the training and inference of diffusion models. However, a common challenge with generating audio using diffusion models is the fixed-size output, which can pose difficulties when generating audio of varying lengths.
AI sound generator
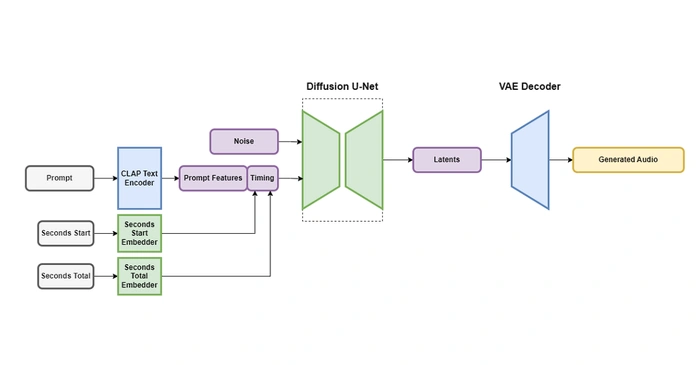
To address this issue, a new latent diffusion model architecture, Stable Audio, has been introduced. This innovative model is conditioned on text metadata, audio file duration, and start time, providing control over the content and length of the generated audio. Unlike its predecessors, Stable Audio can generate audio of a specified length up to the training window size, thereby overcoming the limitations of fixed-size output.
One of the key features of Stable Audio is its use of a heavily downsampled latent representation of audio, which allows for faster inference times. This model is capable of rendering 95 seconds of stereo audio at a 44.1 kHz sample rate in less than one second on an NVIDIA A100 GPU, demonstrating its impressive speed and efficiency.

Stability AI Stable Audio
The architecture of Stable Audio consists of a variational autoencoder (VAE), a text encoder, and a U-Net-based conditioned diffusion model. The VAE plays a crucial role in compressing stereo audio into a data-compressed, noise-resistant, and invertible lossy latent encoding, which facilitates faster generation and training. The model is conditioned on text prompts using the frozen text encoder of a CLAP model trained from scratch on the dataset.
Other articles you may find of interest on the subject of Stability AI :
Another unique feature of Stable Audio is the calculation of timing embeddings during training time. This allows the user to specify the overall length of the output audio during inference, providing greater control and flexibility in audio generation.
The diffusion model for Stable Audio is a 907M parameter U-Net based on the model used in Moûsai, a testament to its robust and complex architecture. To train the Stable Audio model, a dataset of over 800,000 audio files containing music, sound effects, and single-instrument stems, as well as corresponding text metadata, was used. This extensive dataset underscores the comprehensive and diverse range of audio that Stable Audio can generate.
Stable Audio is a product of the cutting-edge audio generation research conducted by Stability AI’s generative audio research lab, Harmonai. This lab is at the forefront of innovation in the field of AI-generated audio, and Stable Audio is a testament to their pioneering work.
Looking ahead, future releases from Harmonai will include open-source models based on Stable Audio and training code for training audio generation models. These forthcoming developments promise to further advance the field of AI-generated audio, offering new possibilities for the creation and manipulation of sound.
Stable Audio represents a significant advancement in the field of AI-generated audio. By addressing the limitations of fixed-size output and offering greater control over the content and length of generated audio, Stable Audio is paving the way for more sophisticated and versatile audio generation models. Try out the new AI sound generator for yourself over on the official website.
Filed Under: Guides, Top News
Latest Aboutworldnews Deals
Disclosure: Some of our articles include affiliate links. If you buy something through one of these links, Aboutworldnews may earn an affiliate commission. Learn about our Disclosure Policy.





